Optical Character Recognition (Оптическое распознавание символов).
В рамках поставленной задачи необходимо было разработать механизмы быстрого поиска документа по его типу, навигации среди найденных документов и их отображении. Объём документов более 0.5 Тб (нескольких десятков миллионов сканированных документов). Сложность заключалась в крайне низком качестве документов:
- документы печатались на печатных машинках (самые ранние документы датировались серединой XX века);
- на документах были следы от чашек, пятна пролитого кофе;
- большое количество документов с выгоревшей бумагой;
- много документов за время прямого использования попадало под дождь или было повреждено солёной водой;
- на многих документах были нанесены пометки карандашём или ручкой;
- бумага сворачивалась и подвергалась другим воздействиям.
Для примера, так выглядело 60% документов:
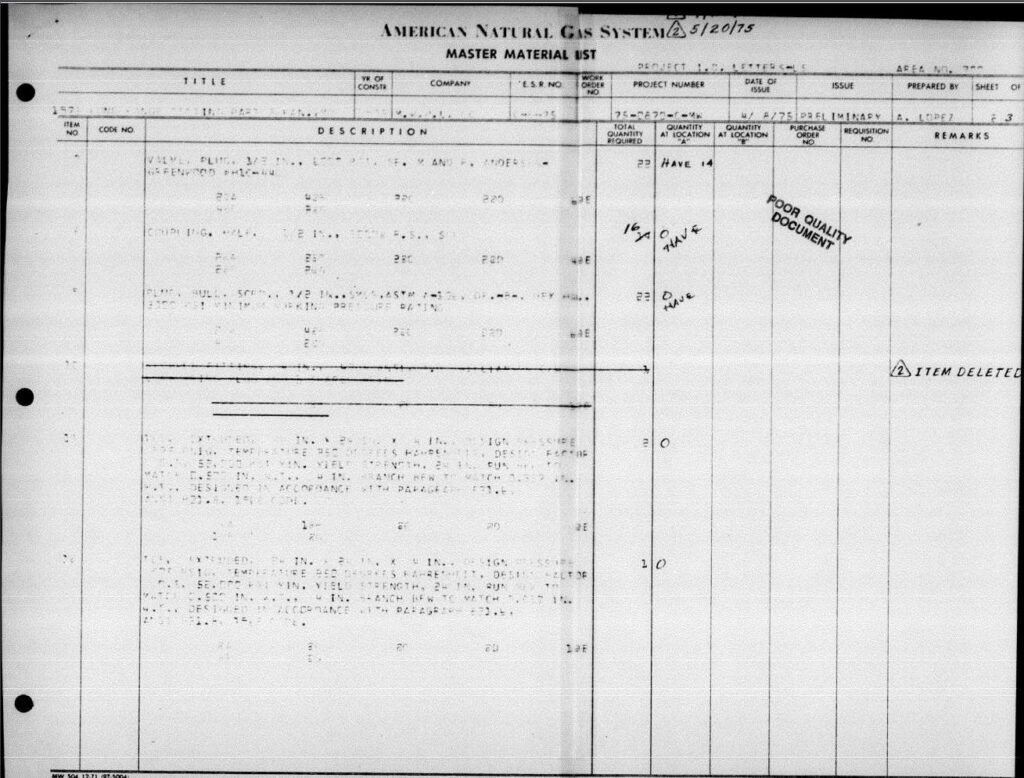
С помощью тренеровки модели нам удалось добиться высокого результата распозновавния (более 90%)